

-
Sándorné Szatmári: @CIkk: Mende Balázs Gusztáv kutató csoportja írta "..az avarok anyai ágú etnogenezise egys...2025. 07. 15, 14:43 2. rész: nomád régészeti konferencia...
-
ganajtúrós bukta: Most találtam a wikiben: "Ugyanez a genom 50% manysi (finnugor), 35% szarmata (indoiráni) ...2025. 07. 12, 20:34 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
ganajtúrós bukta: @Sándorné Szatmári: Amúgy nincs kedved kalandmesternek jelentkezni a legközelebbi m.a.g.u....2025. 07. 09, 18:00 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
szigetva: @Sándorné Szatmári: Egyetlen konkrétum van a hosszú szövegedben: a magyarban E3-ban nincs ...2025. 07. 09, 11:17 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
Sándorné Szatmári: @ganajtúrós bukta: Idézet a cikkből: "...erősen kritizálják a nyelvcsalád fogalmát. Ennek ...2025. 07. 09, 10:23 Mi bizonyítja, hogy a magyar nyelv finnugor?
Kálmán László nyelvész, a nyest szerkesztőségének alapembere, a hazai nyelvtudomány és nyelvi ismeretterjesztés legendás alakjának rovata volt ez.
- Elhunyt Kálmán László, a Nyelvész, aki megmondja
- Így műveld a nyelvedet
- Utoljára a bicigliről
- Start nyelvstratégia!
- Változás és „igénytelenség”
Kálmán László korábbi cikkeit itt találja.


Ha legutóbb kimaradt, most itt az új lehetőség!



Ha ma csak egyetlen nyelvészeti kísérletben vesz részt, mindenképp ez legyen az!

Finnugor nyelvrokonság: hazugság


A határozott névelő, ami azt jelenti, hogy ‘te’



Az oroszok már a fejünkön vannak!

egueguegueguegu-eguegueguegueguegu...


Folytatjuk Simo Parpola sumer etimológiai szótárának elemzését. Tényleg közös eredetű lenne a sumer ĝizzal és a magyar bölcsesség, a sumer tukul és a magyar tákolmány?
Mai írásunkban a sumer etimológiai szótár szóanyagát magyar szempontból tekintjük át. Egy tudományos mű értékelése lehet könnyű és nehéz feladat is. Egyetérteni a szerzővel, helyeselni a gondolatait jóval könnyebb, mint bírálni, vitatkozni. Ha egyetértünk, azt lényegében nem kell bizonyítani, hiszen ott van az eredeti mű, tessék azt elolvasni. Ha bírálunk, akkor viszont részletes cáfolatra, meggyőző érvelésre van szükség. Na, ez az, ami egy szakmabelinek lehet érdekes, de a kívülálló rettentően fogja unni. Különösen nehéz a helyzet, ha valami bombasztikus újdonságról kell lerántanunk a leplet, hogy bemutassuk, ez is olyan, mint a mesebeli király: teljesen meztelen. Ilyen esetekben ugyanis a tudományos bírálatot már megelőzte az általában bulvár, jó esetben ismeretterjesztő sajtóban történt beharangozás. Az pedig sokat tud ártani a tudományos megközelítésnek. Simo Parpola sumer szótára Magyarországon még ismeretlen, ily módon itthon lépéselőnyben vagyunk, de a finn napisajtóban már beharangozták: a Helsingin Sanomat közölt róla cikket.

(Forrás: Helsingin Sanomat)
A sumer–magyar etimológiákkal kapcsolatos problémák a következőképpen csoportosíthatók:
1. Mennyi az annyi, vagyis hány sumer szó van a magyarban Simo Parpola szerint
2. A szótárban pontatlanul szereplő magyar szavak
2.a) elütések
2.b) nem létező magyar szavak
2.c) magyar szavak téves vagy pontatlan angol jelentéssel
3) a rokonított sumer és magyar szavak között nincs jelentésbeli kapcsolat
4) egy magyar szó több sumer megfeleléssel
5) a képzett szavak problémaköre
5.a) a szótárba föl nem vett tő képzett alakjának/alakjainak szerepeltetése
5.b) azonos tőből képzett szavak más-más sumer szóval történő rokonítása
5.c) igekötős magyar igék sumer igékkel való megfeleltetése és az uráli alapnyelvre való rekonstruálása
5.d) összetett szavak a szótárban: miért és hogyan?
6) jövevényszavak és kései keletkezésű szavak sumer megfeleléssel, az uráli alapnyelvből származtatva
7) hangutánzó/hangfestő és gyermeknyelvi szavak fölvétele a szótárba
8) morfonológiai problémák: az uráli alapnyelvre nem jellemző három szótagú, valamint mássalhangzóra végződő alapnyelvi tövek rekonstruálása
9) dilettáns sumer–magyarológusok műveinek idézése, etimológiáinak átvétele (ezt korábban már említettük)
Mindezen problémák megelőlegezik azt, hogy Simo Parpola sumer–magyar és egyéb sumer–finnugor etimológiái kívül esnek a szabályos hangmegfelelések körén. A szótár szócikkeinek történeti nyelvészeti módszerrel történő elemzése feltehetőleg igazolni fogja a magyar szóanyag áttekintése alapján kialakított véleményünket. Már amennyiben vállalkozik valaki erre a munkára. Mert a fent felsorolt problémák miatt ez valószínűleg felesleges időtöltés lenne.
1. A szerző saját számításai szerint 1238 közös eredetű sumer–magyar szót vezet vissza az uráli alapnyelvig. A magyar szavak mutatója (II/369–377.) azonban 1526 szót tartalmaz. Valószínűleg azért többet, mint 1238, mert Simo Parpola talán egy megfelelésnek vette, ha azonos töből képzett magyar szavakat egy sumer szóval kapcsolt össze, illetve ha egy magyar szónak több sumer etimológiát is talált. A magyar mutatóban található szavak közül 674 esetben tünteti fel az Uralisches Etymologisches Wörterbuch (UEW) által rekonstruált uráli alapnyelvi alakot. (A szótáríró ezekben az esetekben is rekonstruál egy másik uráli alakot, hogy abból a sumer szót is le tudja vezetni.) Ez azt jelenti, hogy a többi 852 uráli eredetű magyar szó – amelyeknek mellesleg sumer megfelelőjük is van – mind Parpola új etimológiája. Vagyis az elmúlt évtizedben ő egyedül több uráli eredetű magyar szót talált, mint az elmúlt évszázadokban az összes kutató együtt. Ez hihetetlen. Miként az is, hogy a szerző 2790 közös uráli tőből származó sumer–finn szót talált. Ez a szám feltűnően meghaladja az eddig ismert összes uráli etimológia számát.
2.a) A szótárban szereplő elütések, tévesen leírt szavak önmagukban nem minősítik az etimológiákat, de jelzik Simo Parpola járatlanságát a magyar nyelvben (ezen egy magyar nyelvű lektor segíthetett volna): pl. cákány =csákány?, gyökör =gyötör?, hijó =hajó?, köszég = község?, omel = emel?, takácő = takács?
2.b) Ezeket a magyar szavakat mi nem ismerjük:
diń ’palisade (a szótár 488. szócikke szerint ez egy mordvin szó, tévedésből került a magyar szómutatóba)
gyakor ’many’ (régies?)
monna ’both’ (nyelvjárási?)
sérinchal ’ruff’ – ezt azért ismerjük, de a szótárba vétele szintén nagy tévedés: N. Sebestyén Irén említi mint egy finnugor etimológiájú halnév által jelölt halfaj magyar nevét, tehát a sérinc szerinte sem finnugor eredetű magyar szó ‒ lásd itt: Az uráli nyelvek régi halnevei, NyK 49 /1935/: 66.)
ve ’power, help’ in -vel ’with the help of’
2.c) A jelentés pontatlan megadásától függetlenül ezek az etimológiák akár helyesek is lehetnének, de azért ilyen hibáknak sincs helyük egy önmagát komolynak mutató szótárban:
hunyó ’it’ ‒ ez a szó azért ennél bonyolultabb jelentésű…
daru ’crane’ ‒ itt hiányzik a madár latin neve, a grus grus
mása ‒ úgy mint valakinek a képmása ‒ az angol ’image, copy’ nem adja vissza a szó jelentését
nyék ’back’ ‒ a magyar szó jelentése ’kerítés, sövény’, az angol megfelelője itt sem megfelelő
3. Például a szótár szerint a magyar lak ’dwelling’ és lakk ’loft’ egyaránt a sumer dag (409.) szóval rokon. Már csak az a kérdés, hogy a ’loft’ jelentésű lakkot nem a 2. c) pontnál kellene-e inkább szerepeltetni. Ott is helye van.
4. Itteni példánk az ének két megfelelése: az en.di, èn.du (661.) és az inim, e.ne. èĝ, enim (1264.). További két sumer megfeleléssel rendelkező magyar szavak: epe, fon, haj, hajlít stb. (ezek a példák a 9 oldalas magyar szómutatónak csak 2 oldaláról származnak, tehát lenne még példa bőven). Az egy magyar tőhöz rendelt több sumer etimológia az egész szótárt gyanússá teszi: vajon Parpola megfelelő gondossággal járt el az etimológiák felállításakor? Amennyiben a szerző komolyan gondolja, hogy a magyar ének szabályos hangváltozásokon át egyaránt levezethető az általa rekonstruált uráli *änδǝἠä (661.) és *jańtek (1264.) szavakból, akkor igen csak megengedő szabályokat alkothatott, olyanokat, amelyek szinte már nincsenek is.
5.a) Egy példa: a ĝizzal, misal ’wisdom, understanding’ sumer szó Simo Parpola szótárában az 1088-as sorszám alatt található. A szerző által rekonstruált uráli (PU) alak, melyből a finnugor és sumer szavak származnak, így fest: *ἠwiδ'ǝδuϑ. Finn megfelelője a viisaus, a zürjén pedig vežer. És ez lenne azonos a magyar bölcsességgel.
A finn viisaus a viisasból képzett alak, ez utóbbi pedig az ősgermán *wīsaz ’wise’ szóból származik. A ’bölcs’ és a ’bölcsesség’ jelentésű sumer szavak külön szerepeltetése csak akkor lenne valamennyire indokolható, ha a képző is egy közös uráli‒sumer alapnyelvből származna. A szótár szerzőjének tehát elsősorban a sumer ’bölcs’ jelentésű szóhoz kellett volna kapcsolnia finnugor alakokat. Ha utánanézünk a szótárban, megtaláljuk azt is. Az 1496. szó a kù.zu (Parpola PU rekonstrukciója: *ἠwiδ'p, *ἠwiδ'aϑ), melynek finn megfelelője a visu, viisas. A kù.zu szónál szépen föl vannak tüntetve az indoeurópai kapcsolatok is (ang. ’wise’, ném. ’Weise’), tehát Simo Parpola a finn szavak etimológiai hátterével tisztában van (és a sumer etimológiától nem tántorította el a viisas jövevényszó jellege), a magyar bölcsesség szó bölcs tövét azonban hiába keressük a kù.zu alatt. A szerző a -ság/-ség képzőt sem veszi fel a szótárába, ellenben a szómutatóban megtaláljuk a ság ’hill’ és ség ’hill’ főneveket. Ezek uráli alakját így rekonstruálja: *ἠaŋkwa, ćäŋkwa. Simo Parpolának a bölcs és a ság/ség általa rekonstruált hangalakjait kellett volna összegyúrnia a bölcsesség uráli alapnyelvi rekonstrukciójába.
És még egy apróság: eddigi tudományunk szerint ἠ és ŋ hanggal (palato-veláris nazális) egyetlen uráli alapnyelvi szó sem kezdődött. (Ez külön pont is lehetne Simo Parpola tévedéseinek listáján.) Az ἠ és az ŋ rekonstruálása a szótáríró által egyes uráli alapnyelvi szavak elejére önmagában is bizonyítja, hogy a sumer nem uráli nyelv, bekényszerítése a nyelvcsaládba erőltetett próbálkozás. Az uráli nyelvek alapszókincséből nem következik az ἠ és az ŋ szókezdő alapnyelvi jelenléte.
A másik példa a tákolmány. Amennyiben tényleg uráli eredetű, sumer etimológiával is rendelkező szó lenne, akkor a tákol ige is ugyanúgy. Ezt a szót azonban hiába keressük a sumer etimológiai szótárban. (sok-sok további példa…)
5.b) A sumer mug a PU *moćka tőre megy vissza, miként a magyar mocsok is. De a mocskos sumer megfelelője az ú.sug4, ú.zug4, ú.sag, miu.zuḫ, PU alakja pedig *kwädjäka, wäčäkä. Ez utóbbi sumer szó magyar megfelelője még a piszok és a koszos. Ezt így hogy? (Az 5.b) típusra is vannak még példák.)
5.c) Az igekötős igék szótárba vételére is rengeteg példa van. Úgy tűnik, Simo Parpola az igekötőkkel is számol a hangtani rekonstrukcióiban. Igen tanulságos a kétféle kiránt ige a szótárban

(Forrás: Simo Parpola: Etymological Dictionary of the Sumerian. Winona Lake, 2016. Part 1: 192.)
Az első kiránt jelentése ’to fry in bread crumbs’, sumer alakja kár, kára, Parpola szerint az UEW *korpe- tövéből származik (mely tövet az UEW egyébként a hervad igével hozza összefüggésbe). A szerző nem tudja, hogy nemcsak a kiránt, hanem a ránt igének is van ’to fry in bread crumbs’ jelentése, továbbá a rántott húst a középkori Itáliában találták föl. Azt sem ártana tudni, hogy a ránt ebben a jelentésében eredetileg rát volt. A másik kiránt ’to pull out’ ige a sumer ĝir szóval rokon, Parpola-féle PU töve *ŋwirkǝ-, kwirγǝ-. Vajon hogyan lesz szabályos hangváltozásokkal mindkettőből kiránt? Sőt az utóbbiból még kirak is?

(Forrás: Simo Parpola: Etymological Dictionary of the Sumerian. Winona Lake, 2016. Part 1: 157.)
5.d) Összetett magyar szavak mint a feltételezett uráli‒sumer alapszavak folytatásai: csörgőréce, teknősbéka, vízikígyó. Nem értjük az összetett szavak szerepeltetését, mivel a feltételezett sumer‒uráli nyelvi kapcsolat a teknősbéka esetében csak a béka, a vízikígyó esetében pedig csak a kígyó szóra korlátozódik a szerző szerint, a csörgőréce esetében viszont nem világos, hogy az összetett szó melyik eleméhez kapcsolja a sumer etimológiát.
6. Simo Parpola a magyarban nyilvánvalóan jövevénynek minősülő, de általa mégis urálinak vélt szavak egy részénél megadja az indoeurópai és altaji megfeleléseket is, de például az ir, ir.ir (1267.) szónál, ami szerinte az ikra sumer párhuzama lenne, nem utal a szláv kapcsolatokra:
árrés (modern közgazdasági jelentésű szóösszetétel)
cickány (török, német közvetítéssel)
ciki (német?, az 1960-as éveknél korábbi adat nincs erre a szóra)
csákány (török vagy szláv)
csávó (cigány)
gyöngy (török)
ikra (szláv)
karvaly (török)
penna (latin)
salak (német)
saru (török)
szalma (szláv)
széna (szláv)
tinó (török)
uborka (szláv)
vályú (török)
varsa (szláv)
(Ide is tudnánk még példákat hozni.)
7. Nálunk tanítják az egyetemen, hogy hangutánzó, hangfestő és gyermeknyelvi szavakkal nem lehet nyelvrokonságot bizonyítani. E szavak jelentése annyira kötődik a hangalakjukhoz, hogy a szabályos hangmegfelelések körükben alig vagy egyáltalán nem érvényesülnek. Simo Parpola azonban mégis több ilyen szónak talált közös sumer‒uráli őst.
baba
bába
dudál
horkol
kakukk
mama
8. A példa legyen megint a sumer ĝizzal, misal ’wisdom, understanding’. A szerző által rekonstruált uráli (PU) alak, melyből a finnugor és sumer szavak származnak, így fest: *ἠwiδ'ǝδuϑ. E szó hangalakja CVCVCVC (ahol a c= mássalhangzó, a v= magánhangzó), amely ellentmond minden eddigi tudományos eredménynek: ugyan rekonstruáltak már néhány három szótagú (képzett) szót az alapnyelvre, de mássalhangzóra végződőt eddig egyet sem. Az egy-és két szótagúak között sem voltak mássalhangzóra végződők.
Lehetne még a szótár magyar szóanyagában tovább böngészni, és a típushibákat további alcsoportokra osztani. Akinek van hozzá kedve, csinálja. Kérdés, hogy hány sumer–magyar etimológia marad, ha a fenti osztályozás segítségével kidobáljuk az oda nem valókat. Mindenesetre egy történeti nyelvésznek ajánlott előbb selejtezni, és csak a maradékban kutakodni a szabályos hangmegfelelések után. Már amennyiben elfogadja hitelesnek a sumer szavak hangalakját.
Amint ismertetésünk első részében utaltunk rá, a szótár nem tartalmazza a szerző által követett módszerek és elvek leírását. Annak érdekében, hogy ezekről megtudjunk valamit, Simo Parpolát levélben kértük, hogy küldje el nekünk a sumer–uralisztikával foglalkozó tanulmányait. Másnap 10 mű kéziratát kaptuk meg, ezúton is köszönjük. 2010-ben megjelent tanulmányában (Parpola, Simo 2010. Sumerian: A Uralic Language (I), in L. Kogan et al. (eds.), Language in the Ancient Near East. Proceedings of the 53 e Rencontre Assyriologique Internationale, Vol. I, Pt. 2 (Babel und Bibel 4/2, Winona Lake, Indiana): 181-210.) beszámolt arról az első felfedezéséről, hogy a sumer és az uráli nyelvek között a következő szabályos hangmegfelelések vannak: Fi h- ~ Sum š-, Fi v- ~ Sum mu- vagy u-. Ezután további hangmegfeleléseket talált: például a Sum /g/ és /k/, valamit az uráli /v/ és /w/ között is szabályos kapcsolat mutatkozik. Mindezen felfedezésekkel kapcsolatban akkor fogtunk gyanút, amikor azt olvastuk, hogy az uráli (PU) /*w/ sumer megfelelője az m, b, u és az l is lehet. Ez már nekünk sok. Kíváncsian várjuk a hozzáértők hozzászólásait.
(Forrás: Simo Parpola: Etymological Dictionary of the Sumerian Language. Winona Lake, 2016. Part 2: XIX)
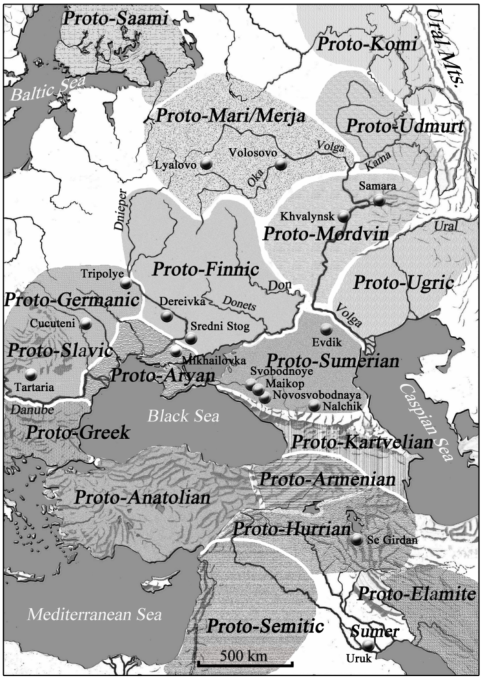
Ismertetésünk első részében már megírtuk, hogy a szerző etimológiáit tökéletesnek tartja, és ezért keresi az idejét és a helyét az egykor bizonyosan létezett sumer‒uráli együttélésnek. Az i. e. 4. évezredben a Kaukázus előterétől egészen az erdőövezet északi határáig uráli népességgel számol. E területen belül a sumerek elődei éltek a Kaukázus északi lábainál, a finnek elődei pedig a Dnyeper és a Don között. A térképről lemaradtak a balti finnek, persze lehet, hogy Parpola őket is a finnek közé sorolta. Mindenesetre, szerinte a Baltikum finnugormentes övezet volt ebben az időben, Finnország területén pedig a lappok elődei éltek. A magyaroknak az Alsó-Volga és az Ural folyók vidékét juttatta, mellyel a sztyeppei ősökre vágyódó testvéreink nyilván nagyon meg vannak elégedve.
Ugyanúgy, ahogy a sumer‒uráli nyelvrokonság feltételezése is teljességgel szembe megy a nyelvtudomány eddigi eredményeivel, a felvázolt régészeti tabló is tökéletesen fölforgat mindent. Simo Parpola régészeti koncepciója sem igazolható, mivel a sztyeppe újkőkori és rézkori régészeti kultúrái olyan későbbi kultúrákban folytatódnak, amelyek aztán az indoeurópai nyelvű népekig vezetnek minket. A kelet-európai erdőövezeti kultúrák folytatásai pedig több kulturális áttételen keresztül a finnugor nyelvű népek tárgyi néprajzi emlékeivel állnak kapcsolatban. És még egy megjegyzés: Simo Parpola nem tagadja ki a szamojédokat az uráli nyelvcsaládból, sőt szerinte 891 sumer‒szamojéd közös szó van, mégis a szamojédok teljes egészében hiányoznak az őstörténeti koncepciójából.
Simo Parpola Etymological Dictionary of the Sumerian Language című munkája az eddigi legtudományosabb kísérlet a sumer nyelv uráli gyökereinek bizonyítására. Véleményünk szerint azonban nem sikerült bizonyítania, hogy a sumer az uráli nyelvek családjába tartozik.