

-
ganajtúrós bukta: @Sándorné Szatmári: "Úgy gondolom, hogy a matematikában működő, csak darabszámra építő "va...2025. 07. 03, 12:29 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
Sándorné Szatmári: @ganajtúrós bukta: Talán a mesterséges intelligencia alkalmas lesz felvállalni a bonyolult...2025. 07. 02, 09:29 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
ganajtúrós bukta: @Sándorné Szatmári: Szóval nem válaszolsz helyette ezt csinálod: hu.wikipedia.org/wiki/Ign...2025. 07. 02, 00:27 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
Sándorné Szatmári: @szigetva: @ganajtúrós bukta: Gondolom az átalános relativitás számunkra nyelvi téren érte...2025. 07. 01, 21:08 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
ganajtúrós bukta: @Sándorné Szatmári: Nem válaszoltál a kérdésemre. Mivel magyarázod a videót amit belinkelt...2025. 07. 01, 18:44 Mi bizonyítja, hogy a magyar nyelv finnugor?
Kálmán László nyelvész, a nyest szerkesztőségének alapembere, a hazai nyelvtudomány és nyelvi ismeretterjesztés legendás alakjának rovata volt ez.
- Elhunyt Kálmán László, a Nyelvész, aki megmondja
- Így műveld a nyelvedet
- Utoljára a bicigliről
- Start nyelvstratégia!
- Változás és „igénytelenség”
Kálmán László korábbi cikkeit itt találja.


Ha legutóbb kimaradt, most itt az új lehetőség!



Ha ma csak egyetlen nyelvészeti kísérletben vesz részt, mindenképp ez legyen az!

Finnugor nyelvrokonság: hazugság


A határozott névelő, ami azt jelenti, hogy ‘te’



Az oroszok már a fejünkön vannak!

egueguegueguegu-eguegueguegueguegu...


Az utóbbi években a számítógépes nyelvészek a szabályalapú modellekről egyre inkább a statisztikai modellekre térnek át. Mi az előnye a statisztikai modellnek, és végleg elfelejthetjük-e a szabály alapú modelleket?
December 2-3-án hetedik alkalommal rendezték meg Szegeden a Magyar Számítógépes Nyelvészeti Konferenciát, rövid nevén az MSZNY-t. Ez a konferencia ad otthont minden év december elején a magyarországi számítógépes nyelvészet aprajának-nagyjának (inkább nagyjának). Az MSZNY már évek óta kiemelkedő eseménynek számít ezen a szakterületen, mivel kiváló lehetőséget biztosít arra, hogy a nyelv- és beszédtechnológia területén végzett legújabb, illetve folyamatban levő kutatási eredményeket a résztvevők megismerhessék és megvitathassák.
(Forrás: Simon Eszter)
Idén a konferenciafelhívásra beérkezett absztraktok közül 46-ot fogadott el a programbizottság, így 32 előadás és 14 poszter, illetve demó bemutatására kerülhetett sor. A prezentációkat tematikus blokkokba sorolták a rendezők: összesen 8 blokkban láthattunk színvonalas előadásokat az információkinyeréstől a beszédtechnológián át a gépi tanulásig (az egyes szekciókról bőséges tájékoztatást nyújtottunk helyszíni tudósításainkban).
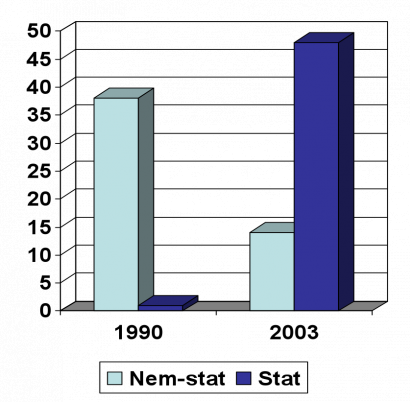
Az egyes szekciócímek megtévesztőek lehetnek, ugyanis a gépi tanulás önmagában csak egy módszer, amely a nyelv- és beszédtechnológia bármelyik területén alkalmazható. A konferenciakötetben konkrétan a "gépi tanulás" frázis 8 cikkben 16-szor van említve, és a most prezentált kutatások nagy része valamilyen statisztikai alapú módszert használ. Összehasonlításképpen: az első, 2003-ban rendezett MSZNY konferenciakötetében elvétve találunk csak gépi tanulási módszereket alkalmazó kutatásokat – annak idején elsősorban a kézzel annotált korpuszok és a különböző szabályalapú megközelítések uralkodtak. Ez a trend általános a számítógépes nyelvészetben – a nagyobb konferenciák után csinos diagramokon szokták bemutatni a szabályalapú és a statisztikai alapú rendszerek arányát, amelyeken egyértelműen az látszik, hogy a tisztán szabályalapú megközelítés kezd kiveszni. Ennek a jelenségnek mélyebbre nyúló gyökerei vannak, melyek filozófiai, nyelvészeti és technológiai kérdéseket egyaránt érintenek.
Röviden: a szabályalapú módszert alkalmazó nyelvész saját maga alkotja meg a nyelvtana szabályait a rendelkezésre álló tudásból, melyeket valamilyen formalizált módon ad oda a gépnek. A statisztikai megközelítés lényege épp ennek a saját, esetleg szubjektív tudásnak a kiküszöbölése: a gépnek odaadunk egy kellően nagy méretű szöveghalmazt, és csupán azokat a tulajdonságokat definiáljuk, melyek fontosak lehetnek a vizsgált jelenség szempontjából. Ezután a gép maga tanulja ki a szövegből a megfelelő szabályszerűségeket, melyek alapján egy addig ismeretlen szövegben is be tudja azonosítani a megfelelő egységeket. Például az automatikus tulajdonnév-felismerés esetén olyan jegyeket írunk le, mint hogy egy adott szövegelem nagybetűvel kezdődik-e, szerepelnek-e rajta bizonyos ragok, többesszámban van-e, van-e előtte névelő stb. Az ilyen formai és morfológiai tulajdonságok alapján a rendszer igen nagy pontossággal lokalizálni tudja a tulajdonneveket egy ismeretlen szövegben is.
A nemzetközi (és egyre inkább a hazai) trendek is azt mutatják, hogy a két megközelítés kombinációja lenne a célravezető, ám erre való próbálkozásokat a mostani MSZNY-en még keveset láthattunk. Éppen egy ilyen kutatást bemutató előadással nyerte meg a legjobb ifjú kutatói díjat Recski Gábor (MTA SZTAKI), aki egy magyar főnévi csoportok azonosítására alkalmas mondattani elemzőt épített hibrid módszerrel.
2007-ben a programbizottság tagjai arról hoztak döntést, hogy az MSZNY-t ezentúl csak kétévenként rendezik meg – kiküszöbölendő az időbeli egybeesést egy fontos beszédtechnológiai konferenciával. Továbbá az is indokul szolgálhatott, hogy az előadások mennyiségében és minőségében érezhető visszaesés következett be pár évvel ezelőtt. De mivel most szép számban hallhattunk futó és nemrég lezárult projektekről a beszédtechnológusoktól is, ezt a döntésüket egyértelműen felülbírálták, vagyis folytatva a hagyományokat minden év decemberében lesz MSZNY.