

-
Sándorné Szatmári: @CIkk: Mende Balázs Gusztáv kutató csoportja írta "..az avarok anyai ágú etnogenezise egys...2025. 07. 15, 14:43 2. rész: nomád régészeti konferencia...
-
ganajtúrós bukta: Most találtam a wikiben: "Ugyanez a genom 50% manysi (finnugor), 35% szarmata (indoiráni) ...2025. 07. 12, 20:34 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
ganajtúrós bukta: @Sándorné Szatmári: Amúgy nincs kedved kalandmesternek jelentkezni a legközelebbi m.a.g.u....2025. 07. 09, 18:00 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
szigetva: @Sándorné Szatmári: Egyetlen konkrétum van a hosszú szövegedben: a magyarban E3-ban nincs ...2025. 07. 09, 11:17 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
Sándorné Szatmári: @ganajtúrós bukta: Idézet a cikkből: "...erősen kritizálják a nyelvcsalád fogalmát. Ennek ...2025. 07. 09, 10:23 Mi bizonyítja, hogy a magyar nyelv finnugor?
Kálmán László nyelvész, a nyest szerkesztőségének alapembere, a hazai nyelvtudomány és nyelvi ismeretterjesztés legendás alakjának rovata volt ez.
- Elhunyt Kálmán László, a Nyelvész, aki megmondja
- Így műveld a nyelvedet
- Utoljára a bicigliről
- Start nyelvstratégia!
- Változás és „igénytelenség”
Kálmán László korábbi cikkeit itt találja.


Ha legutóbb kimaradt, most itt az új lehetőség!



Ha ma csak egyetlen nyelvészeti kísérletben vesz részt, mindenképp ez legyen az!

Finnugor nyelvrokonság: hazugság


A határozott névelő, ami azt jelenti, hogy ‘te’



Az oroszok már a fejünkön vannak!

egueguegueguegu-eguegueguegueguegu...


Furcsa jelenségeket produkál a Google Books NGram Viewer: egyes szavak 1820 körül eltűnnek, mások megszaporodnak, megint mások hosszú időre eltűnnek, hogy aztán később ismét igen gyakoriakká váljanak. A nyelvtörténet játszik szeszélyes játékot, vagy másról van szó?
Akik játszani kezdtek a Google Books Ngram Viewerével, bizonyára hamar rákerestek olyan szavakra, melyek általában közérdeklődésre tartanak számot. Ilyen például az f-word, az f betűs szó, melyet beszédben sem illő használni, leírni pedig még nagyobb illetlenség. Ám úgy tűnik, 1800-ban még nem volt az, viszont 1820-ra gyakorlatilag eltűnt. Aztán az 1950-es években megint megjelent, és hirtelen elkezdett szaporodni. A folyamat végét értjük: a nyelvhasználat kötetlenebbé vált, s bár a szó továbbra is durvának számított, a társadalom tűrőképessége megváltozott, a korábban tabunak számító szavak könnyebben bekerültek a könyvekbe is. A folyamat eleje azonban nem világos. A szó korábban nem számított durvának? Vagy korábban kevésbé voltak szemérmesek az írók? A választ akkor kapjuk meg, ha néhány más szó statisztikáját is megvizsgáljuk.
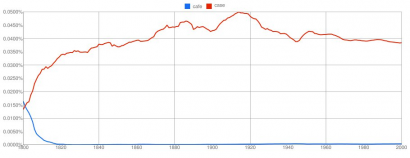
Vessük össze a cafe 'kávéház' és a case 'eset' szavakat. Azt várnánk, hogy az utóbbi sokkal gyakoribb, és ez így is van: azonban az ábra azt mutatja, hogy 1800-ban még gyakrabban fordult elő a 'kávéház', mint az 'eset'. Ez azért mégis fura. De vegyünk egy másik példát!
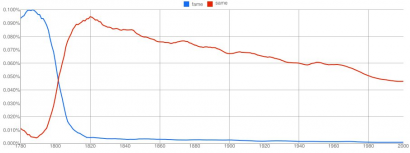
Hasonlót figyelhetünk meg a fame 'hírnév, dicsőség' és a same 'ugyanaz' szavak esetében: bár azt várnánk, hogy az utóbbi sokkal gyakoribb, 1800 előtt sokkal ritkább.
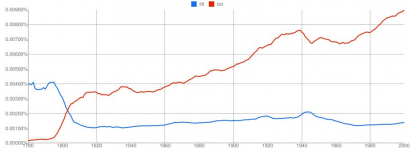
A következő példánk a lift 'felemel' (ill. 'fuvar', 'lift' stb.) és a list 'lista' szó előfordulásait hasonlítja össze. Itt is azt találjuk, hogy a sorrend 1800 körül megfordul.
Mire következtethetünk? Az ábrák egyértelműen azt mutatják, hogy 1800 körül történt valami. Talán megváltozott az angol nyelv? A másik, ami feltűnhet, hogy a vizsgált szópárok mindegyike abban különbözik, hogy az egyikben f van ott, ahol a másikban s. Nem csigázzuk tovább a kedélyeket, és eláruljuk a megoldást.
Az angolban (akárcsak a magyarban) az s betűnek volt egy másik alakváltozata is, az ſ (long s, azaz 'hosszú s'). A 18. századig ezt jóval gyakrabban használták, mint az s-t. 1800 körül azonban egyre gyakrabban használták az s-t, annyira, hogy 1820-ra az ſ gyakorlatilag teljesen eltűnt.
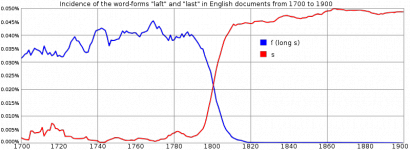
(Forrás: Wikimedia commons)
A szomorú igazság tehát az, hogy a Google Books Ngram Viewer nem minden esetben megbízható. Azt persze eddig is sejthettük, hogy a korpusz nem tökéletes, vannak benne szkennelési és karakterfelismerési hibák, de általában bízhatunk abban, hogy az ilyen hibák véletlenszerűek, és a nagy számok törvénye miatt az eredményt jelentősen nem befolyásolják. Jelen esetben azonban a Google szakemberei nagy hibát követtek el: egyáltalán nem vették figyelembe az ſ betűváltozat létét, és a karakterfelismerő program az összes ilyen betűt s helyett f-ként ismerte fel. Ez azt jelenti, hogy a Google Books Ngram Viewer az s betűt tartalmazó szavak gyakoriságát alulbecsüli, viszont az f betűt tartalmazókét – ha van hasonló szó, melyben s van – felül.
Könnyű azt is kitalálni, hogy a korai adatokban valójában nem az f betűs szó áll, hanem a suck 'szop, szív'. Persze ennek is van kevéssé szalonképes használata, de feltételezhetően nem ezek adják a nagy mennyiséget.
Forrás