

-
ganajtúrós bukta: @Sándorné Szatmári: Amúgy nincs kedved kalandmesternek jelentkezni a legközelebbi m.a.g.u....2025. 07. 09, 18:00 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
szigetva: @Sándorné Szatmári: Egyetlen konkrétum van a hosszú szövegedben: a magyarban E3-ban nincs ...2025. 07. 09, 11:17 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
Sándorné Szatmári: @ganajtúrós bukta: Idézet a cikkből: "...erősen kritizálják a nyelvcsalád fogalmát. Ennek ...2025. 07. 09, 10:23 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
ganajtúrós bukta: @Sándorné Szatmári: Az alapszókincs az olyan szavak amiket nap mint nap folyamatosan haszn...2025. 07. 08, 23:12 Mi bizonyítja, hogy a magyar nyelv finnugor?
-
Sándorné Szatmári: @szigetva: Igen, feltételezem, hogy nem véletlenül maradtak fenn.. Nem ki, hanem rátalálta...2025. 07. 08, 11:17 Mi bizonyítja, hogy a magyar nyelv finnugor?
Kálmán László nyelvész, a nyest szerkesztőségének alapembere, a hazai nyelvtudomány és nyelvi ismeretterjesztés legendás alakjának rovata volt ez.
- Elhunyt Kálmán László, a Nyelvész, aki megmondja
- Így műveld a nyelvedet
- Utoljára a bicigliről
- Start nyelvstratégia!
- Változás és „igénytelenség”
Kálmán László korábbi cikkeit itt találja.


Ha legutóbb kimaradt, most itt az új lehetőség!



Ha ma csak egyetlen nyelvészeti kísérletben vesz részt, mindenképp ez legyen az!

Finnugor nyelvrokonság: hazugság


A határozott névelő, ami azt jelenti, hogy ‘te’



Az oroszok már a fejünkön vannak!

egueguegueguegu-eguegueguegueguegu...


Ha a Wordnik szóelemeit lefordítjuk, Szónokot kapunk. A Wordnik azonban nem tart beszédeket, viszont rengeteg dolgot tud mondani a szavakról. A Számítógépes nyelvészet cikkéből kiderül, hogyan deríthető ki a szavak jelentése, miközben olyan kérdéseket is feszegetünk, hogy miként lehet megélni egy ingyenes szótárból, vagy éppen hogy van-e helye Fluor Tomi szövegeinek a szótárban…
Coixet filmje nagyon szépen érzékelteti, hogy a szavakban több van, mint gondolnánk. Persze van a szavaknak egy nyilvános élete is, amiről a szótárak tájékoztatnak minket, de ki szereti a hatalmas köteteket cipelni, ott vannak hát az online szótárak, de ugye tudjuk, hogy a nyilvános dolgokon túl mindenkit azok a titkok érdekelnek... A Wordnik arra vállalkozott, hogy forradalmasítja a szótár fogalmát, és bebizonyítja, hogy a szavak titkos élete kikutatható, és a keresésben is alkalmazható.
Erin McKean lexikográfus (és több sikerkönyv szerzője, valamint divatblogger) és Mark Wong-VanHaren az Excite (1994 óta aktív online szolgáltatás ami a kereséstől kezdve email szolgáltatáson át szinte a teljes vertikumot lefedi) alapítója egyszer összetalálkozott, és megszületett a Wordnik szótár. McKean több neves szótárat is szerkesztett, és nagyon érdekelte, hogy milyennek is kell lennie a 21. század szótárának, van Haren pedig régi motoros a keresésben, nem csoda, hogy a találkozásból egy nagyon izgalmas dolog született. A továbbiakban áttekintjük, hogy milyen is lett ez az új szótár, majd hogy mire is épül fel ez az egész, és végül arra is kitérünk, hogy mire lehet felhasználni (és hogyan lehet pénzt keresni ma egy szótárból).
Az oldal az ajánló után folytatódik...
A 21. század szótára
Addig rendben van, hogy az internet korában egy szótárnak elektronikusnak kell lennie, és a netes megjelenés is alap – sajnos azonban az ingyenesség már nem annyira magától értetőtő. McKean nagyon ráérzett arra, hogy valami nincs rendben azzal, hogy simán tesznek egy keresőt a meglévő adatbázisokra. Egy nyomtatott szótár szerkesztése nagyon körülményes, a használhatóság terjedelmi korlátokat szab, nem lehet csak úgy bővíteni, ezért egy-egy új szó felvétele, vagy éppen törlése nagy vitákat képes kiváltani. De mielőtt ennyire előre szaladnánk, álljunk meg egy percre (vagy egy szóra, ha már a nyelvvel foglalkozunk :D) és gondolkodjunk el azon, honnét is „szerzik be” a szótárkészítők az alapanyagot, amiből kinyerik a szavakat. A szavak nem magukban állnak, hanem mondatokba szerveződve „élik életüket”, a leggyakrabban pedig nem leírjuk őket, hanem beszéd közben szállnak el. Ahogy minden nyelvészeti bevezetőben áll, a szó és annak jelentése közötti kapcsolat önkényes (semmi sem kötelez miket arra, hogy a 'kutya' kutya legyen a magyarban vagy dog az angolban, chien az franciábanban, perro a spanyolban vagy inu a japánban). Egy ilyen önkényes jel jelentése nem önmagában adott, hanem a többi jelhez viszonyítva (és persze a nyelvtani szabályoknak engedelmeskedve). Azaz a kutya szó jelentését azok a mondatok és szószerkezetek határozzák meg, melyekben előfordul. Így pl.
Szeretem a kutyákat.
Cifra, de aranyos kutya vagy te!
A kutya megharapta a postást.
A mudi egy magyar kutyafajta.
A fentiek meghatározzák a kutya szó egy bizonyos jelentését, egyben azt is láthatjuk, hogy itt kicserélhetjük minden előfordulását az eb szóra. Fontoljuk meg azonban az alábbiakat:
Kutya rossz idő van.
Kutya hideg van.
Kutyául állunk.
Tito, a láncos kutya.
Az első kettőben nem éreznénk elfogadhatónak ha a kutyát kicserélnénk ebre. A harmadik esetben ezt nyugodtan megtehetjük (Ebül állunk – ha egyre ritkább is, de elfogadható), a negyedik esetben viszont ismét ellenkezik nyelvérzékünkkel a csere. Ezt a jelenséget nevezzük disztribúciónak, vagy eloszlásnak. Minden szó mutat egy eloszlást, az egyes előfordulások hasonlóak, mások jelentősen eltérnek – ezek adják a jelentést.
Az elszállt szóra nem építhetjük fel a szótárunkat (legalábbis sokáig nem tehettük ezt meg), ezért a lexikográfia elsődlegesen írott forrásokra támaszkodik. Egy nyelv szótárának elkészítése nem könnyű feladat, ha csak az írott adatokra szorítkozunk is, rengeteg kérdés merül fel, kezdve attól hogy milyen időintervallumban vizsgálódunk (bevennénk pl. a magyar nyelv szótárába a 16/17 századi forrásokat, vagy az Ómagyar Mária-siralmat, vagy mondjuk Fluor Tomi dalszövegeit?), de még egy adott intervallumon belül is hatalmas adatmennyiséget kapnánk, és nyilván bizonyos változatok felülreprezentáltak lennének (pl. sokkal több hír és újságcikk keletkezik, mint vers vagy tanulmány), ezért meg kell küzdenünk a mintavételezés problémájával is. (A közvélemény-kutatások elemzéseiből tudjuk, hogy minta legyen reprezentatív – de mit reprezentáljon? A mai magyar nyelvet – de mit értünk ezen, a Magyarországon beszélt magyar nyelvet, a magyar emberek által beszélt standard nyelvet, a nyelvjárásokat is belevesszük, belevesszük-e az szlenget és egyéb nem-standard változatokat stb?) Szembe kell néznünk továbbá azzal a ténnyel, hogy a nyelv változik, akár viszonylag rövid időn belül is belső vagy külső hatásokra új szavak jelenhetnek meg, régi szavak jelentése módosulhat stb. Nádasdy Ádám szavait kölcsönvéve a nyelvek „ide-oda változnak, ahogy a tenger ide-oda hullámzik, apad és dagad”. Persze mi magunk részesei, elszenvedői és okai vagyunk ennek a változásnak, ezért nem látjuk, de Kumanan Rajamanikkam (Wordnik Lead Engineer) Cloudera vendégposztjában felhívja a figyelmet arra, hogy egy elektornikus szótárnak illik feldolgoznia az összes hozzáférhető forrást, és egy már eléggé érett, nagy adatbázissal rendelekező eszközzel is megeshet, hogy másodpercenként (!) 8.000 szót kell feldolgoznia. Ilyen léptékkel már igen kis eltérések is kimutathatók a nyelvhasználatban, egy buzzword (felkapott hívószó) megjelenése is kimutatható ilyen szinten, ami – valljuk be – a hagyományos szótárkészítés esetében nem is biztos, hogy átmegy a következő kiadásba (amire biztos hogy pár évet várni kell).
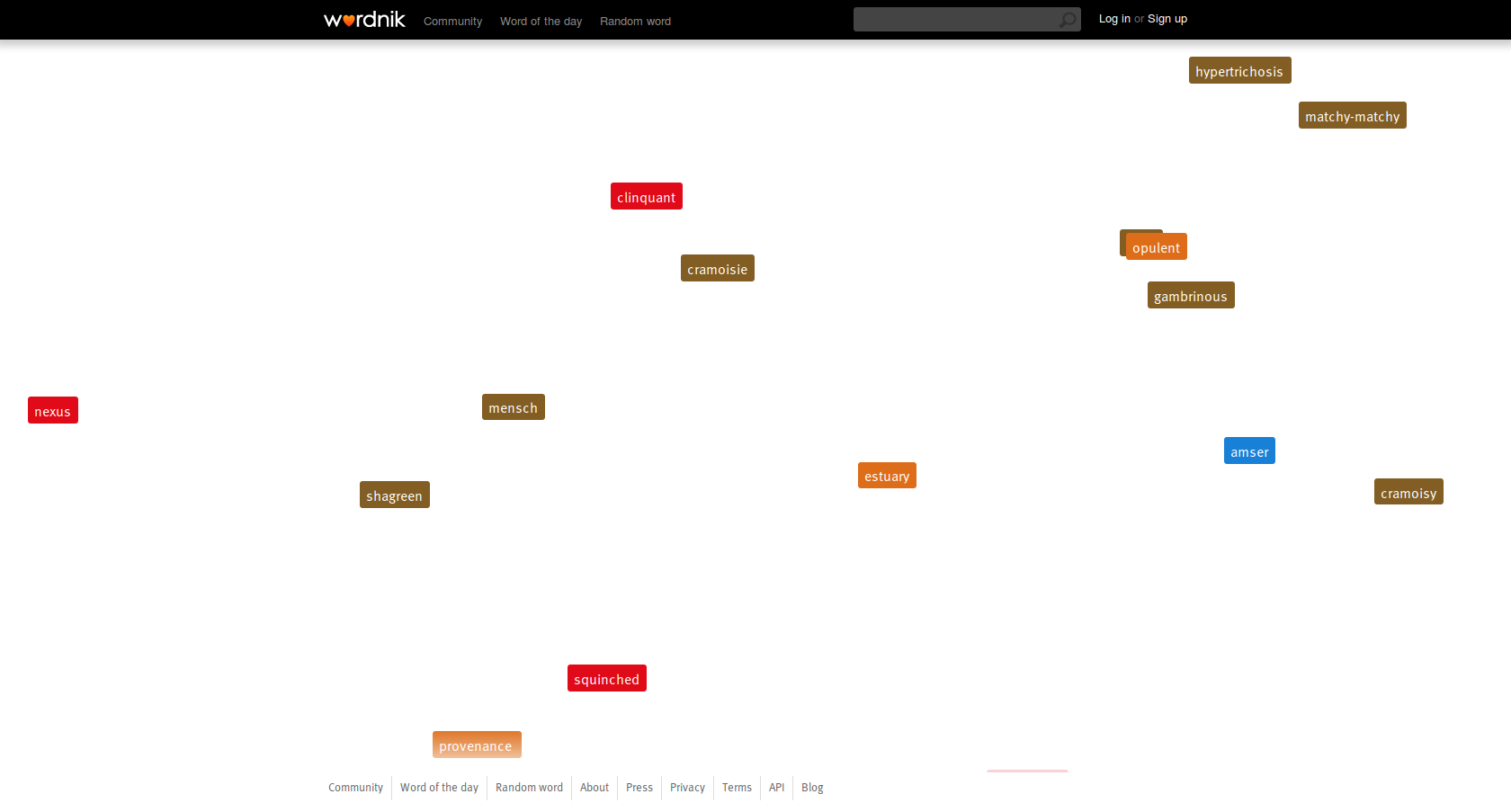
Ha adva van egy kellően nagy adatbázis (vagy nevezzük nevén, és hívjuk korpusznak, ahogy a nyelvészek teszik), valahogy lehetővé kell tenni a keresését is az összes elérhető extra információval. A Wordnik ezt egy eléggé hosszúra nyúlt, de azért áttekinthető felülettel oldotta meg.
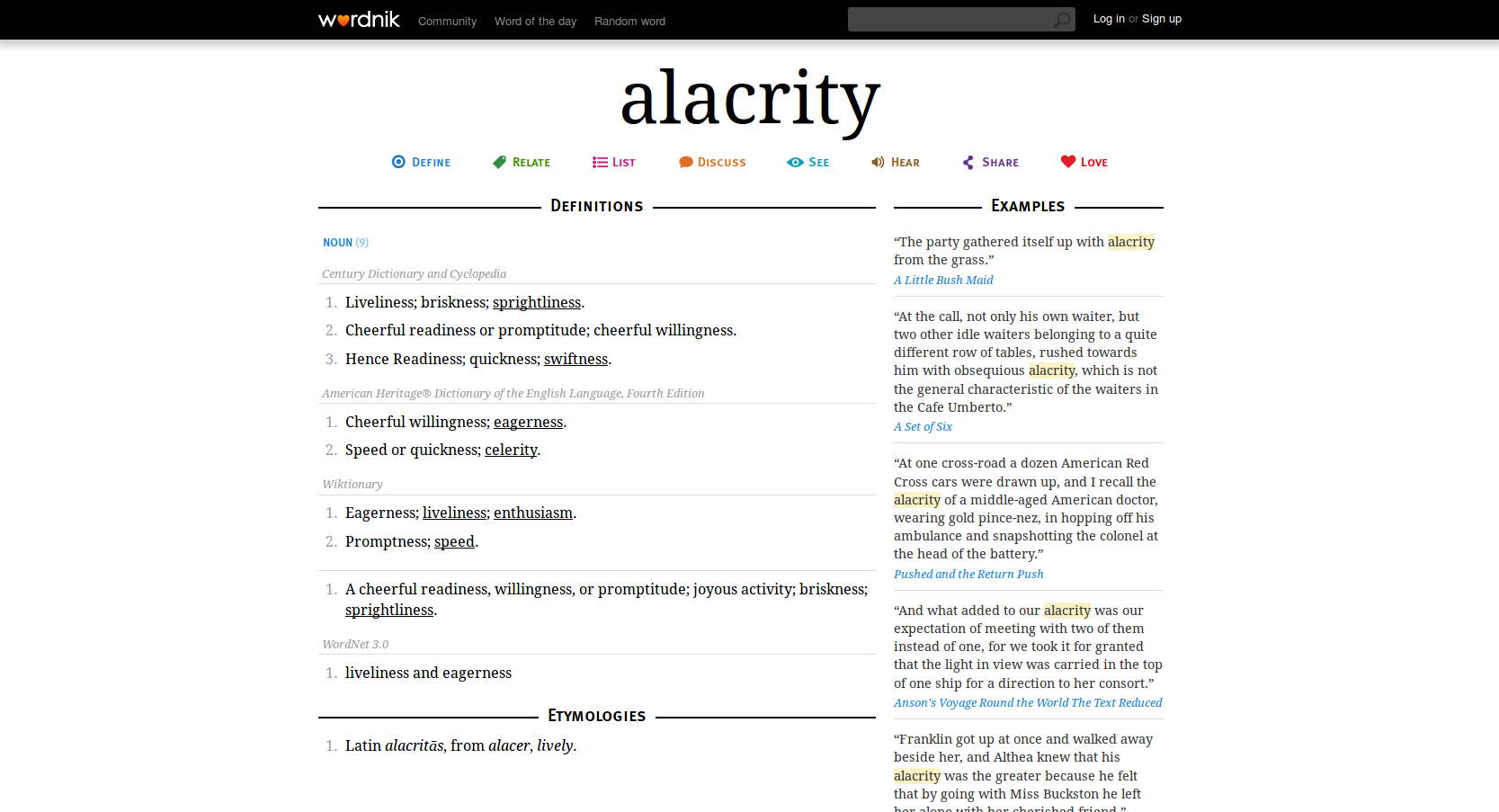
A keresett szó alatt elérhetjük rögtön a Define (meghatároz), Relate (kapcsolódik), List (listáz), Discuss (megvitat), See (néz), Hear (hall), Share (megoszt) és Love (lájkol) gyorslinkeket. A definíciók általában nyílt forrásból nyert meghatározások. Ahol rendelkezésre áll információ, ott az etimológiát (a szó eredetét) is megadják. A fent vázolt disztribúción alapuló példakikeresés is működik, ezt láthatjuk jobb oldalt.

A Relate gyorslink vezet minket a Related words (kapcsolódó szavak) részhez, ahol szinonimákat, antonómiákat és hiponímiákat találhatunk, valamint a felhasználók által megadott cimkéket (tags) is láthatunk.

A felhasználók szerepét nagyon komolyan veszi a Wordnik, bárki regisztrálhat, készíthet magának listákat, kommentálhat szavakat, listákat, sőt részt vehet a Wordnik játékaiban a Twitteren. Egyrészt ez egy nagy buli, másrészt pedig a keletkezett anyag amolyan élőnyelvi korpuszt generál, amit ismét lehet bányászni és beépíteni a szótárba...

De ha ez nem elég, akad még pár dolog.
Minden szavuk aranyat ér?
Az API (application programming interface) lehetővé teszi hogy más fejlesztők is elérhessék, és beépíthessék a szótár szolgáltatásait saját rendszerükbe. Ilyen szolgáltatásokat egyre többen szolgáltatnak,
pl a Google keresés beépíthető egy weboldalba, vagy a Google Maps-et
beágyazhatjuk saját oldalunkba, és kedvünk szerint jeleníthetünk meg információkat rajta. Az ilyen API-on keresztül elérhető szolgáltatásokra épített webes alkalmazásokat hívjuk mashup-nak (web
application hybrid néven is ismertek). Tekinthetjük ezt egyfajta remixnek is. A Twitter köré egy külön kis ökoszisztéma épült, mivel
eléggé fapadosan indult, de egy librálisan működtetett API-t tett elérhetővé. Így a szolgáltatás köré az API-ra alapozva komoly
házzáadott értéket létrehozó mashupok épültek (a különböző Twitter-kliensek, mint a TweetDeck, fotómegosztó alkalmazások pl. TweetPic, geolokációs szolgáltatások mint pl
Foursquare stb).
A körítés mellett azonban felmerülhet a kérdés, mitől több ez, mint pl. a SZTAKI szótárak? Az első, legfontosabb különbség, hogy a szótár elérhető egy API-n keresztül, az összes funkció beépíthető egy mashup-ba, így bárki, akinek szótári információra van szüksége, alkalmazásához készen kapja meg azt. Az Apple tartalomfogyasztásra kihegyezett termékeihez pedig külön SDK-t adtak ki (software development kit – szoftverfejlesztési eszköztár), ami lehetővé teszi, hogy az alkalmazásokból egyszerűen élérhető legyen minden információ. De a Barnes&Noble Nook Color készülékéhez is külön alkalmazást fejlesztettek ki.
A tartalomelőállítók és a tartalomfogyasztásra specializálódott eszközök (legyenek azok szoftverek vagy hardverek) gyártóit célozta meg a Wordnik Smartwords kezdeményezése, ami nem más mint egy API szabvány elektronikus szótárakra szabva (maga a készülő dokumentáció is nagyon hasonlít pl. az Open Knowledge Foundation Open Data ajánlásaihoz).
A Blekko kereső tulajdonképpen lehetővé teszi, hogy különböző feltételek mentén szűrjük és rangsoroljuk a találatokat. A \define slash (így nevezeik „blekkóul” a szűrési feltételeket) eredményét a Wordnik szállítja.

A korpusz mérete immár lehetővé teszi, hogy az egyes szavakat egy olyan strutúrába rendezve kezeljék, ami leírja a közöttük lévő kapcsolatokat – erre épül az új WordGraph API. Itt már nem csupán egy szó definíciójának kinyeréséről van szó, hanem a szavak közötti viszonyok leképezéséről is. Olyan ún. tripleteket kapunk, melyek egyszerű szemantikai viszonyokat fejeznek ki (pl. „a kutya egy állat”, „a kőműves építőipari szakember” stb). A Google Freebase alkalmazása hasonló szolgáltatást nyújt, habár sokkal ambíciózusabb, mivel az emberi tudás egészét szeretné felöleni ilyen fomában. A Wordnik előnye hogy nem tör ilyen nagyra, csupán a szótáron belül az egyes elemek közötti viszonyokat igyekszik leírni. Az eredmény pedig felhasználható számítógépes nyelvészeti problémák megoldására, pl. a keresés során ne csak karakter szerinti egyezést keressünk, hanem jelentés alapján, azaz szinonimákra is keressünk.
A WordGraph első felhasználója, a TaskRabbit portál, ami segít összehozni azokat, akiknek segítségre van szükségük, azokkal, akik meg tudják oldani a feladatot (amolyan mindennapi ügyek elintézése olcsón, gyorsan, hatékonyan).

A feladat leírása és a potenciális segítő megtalálása során a WordGraph összepárosítja a természetes nyelven leírt elvárásokat és képességeket – kár, hogy a Smartwords nevet már ellőtték.
A Wordnik sokak kedvence lett 2009-es indulása óta, a korpusznyelvészet berkeiben pedig egyenesen csodálják, hiszen az alkalmazott korpusznyelvészet megszületésének vagyunk tanui. Azonban még mindig kérdés, hogy képes-e megélni a saját lábán ez a modell, a WordGraph és a különböző szolgáltatások képesek-e annyi profitot termelni, hogy fennmaradjon és növekedjen a cég.
Kapcsolódó cikkek a Keresővilágon