Minél gyorsabb egy nyelv, annál kevesebbet mond
Egy új tanulmány szerint negatív összefüggés van a beszélt nyelvek sebessége és információtartalma között. Minél gyorsabban beszélnek egy nyelvet, annál kevesebb információt hordoz szótagonként.
Valószínűleg sok embernek feltűnt már, hogy egyes nyelveket sokkal gyorsabban beszélnek, mint másokat. A spanyol például tipikuson egy olyan nyelv, melyet gyakran szoktak hadarni, míg a kínai egy sokkal lassabban beszélt nyelv. A Lyoni Egyetem nyelvészkutatói arra voltak kíváncsiak, hogy vajon az azonos időegységre eső információtartalomban is eltérnek-e a beszélt nyelvek, vagy a gyorsabb beszéd alacsonyabb információtartalmat takar.
Az oldal az ajánló után folytatódik...
A tanulmányban hét nyelvet hasonlítottak össze a kutatók. Ugyanazt a 20 ötmondatos rövid történetet lefordíttatták angolra, olaszra, németre, franciára, spanyolra, mandarin kínaira és japánra, majd felvették a történeteket 6-10 anyanyelvi beszélő előadásában. Az így nyert felvételeket alapján összehasonlították a hét nyelvet szótagszámuk és az előadások sebessége szerint. Referenciaként a vietnámi nyelvet használták nyolcadik nyelvként, mert az szinte teljesen izoláló.
A nyelvészek abból az alapfeltételezésből indultak ki, hogy a beszélt nyelvek sebességéből adódó különbségeket a nyelvek a nagyobb információtartalommal kompenzálják. Tehát, hogy míg a beszélt nyelvek másodpercenkénti szótagszáma között nagy eltérések adódhatnak, addig nagyjából ugyanannyi idő kell egy adott történet előadásához nyelvtől függetlenül. Ezt igazolták az kísérlet eredményei is.
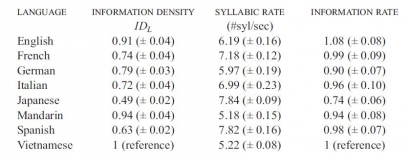
Információsűsűség, szótag/másodperc, infomációs ráta.
A leggyorsabban beszélt nyelvnek a japán bizonyult, másodpercenként átlagosan 7,84 szótaggal, míg a leglassabb a kínai volt (5,18 szótag/sec). A hét nyelv nagy eltérést mutatott mind az össz-szótagszám, mind a beszélők másodpercenkénti szótagszáma szerint. A történetek japán változatainak előadásai például majdnem kétszer annyi szótagot tartalmaztak, mint a mandarin szövegek. A történetek előadásainak teljes hossza között azonban már lényegesen kisebbek voltak a különbségek. A japán kivételével mindössze ±10% volt az eltérés a nyelvek között, az angol bizonyult a leghatékonyabbnak az információtartalom maximalizálásában. Nagy másodpercenkénti szótagszáma ellenére a beszélt japán volt a legkevésbé hatékony információtömörítésben. A japán nyelvnél található eltérés arra vezethető vissza, hogy a japánban sokkal kevesebb a lehetséges szótagok száma, mint a többi nyelvben, mert a japán nem engedélyezi a mássalhangzó-torlódást. Ebből adódóan a japán szótagok potenciális információtartalma lényegesen alacsonyabb, mint más nyelveké.
A japán beszéd gyors, mégis lassabban fejezi ki ugyanazt. (Fanyomat, 1855.)
A kutatók azzal zárják megfigyeléseiket, hogy bár tényleg negatív összefüggés van a nyelvek beszélt sebessége és információtartalma között, ez korán sem jelenti azt, hogy a különböző nyelvek információközvetítési rátája nagyjából azonos lenne. A angol nyelv például 30 százalékkal információdúsabbnak bizonyult a tanulmány eredményei szerint a japánnál.
Források:
Eureka Alert: Language speed vs. efficiency: Is faster better?
Time Science: Slow Down! Why Some Languages Sound So Fast
Hozzászólások (51):
Követem a cikkhozzászólásokat (RSS)
1
El Mexicano
2011. szeptember 9. 08:21
Ezt nem egészen értem. Hogy a fenébe lehetne az angolnak nagyobb információsűrűsége, mint pl. az újlatin nyelveknek, amikor sokkal analitikusabb? Eleve az összehasonlított 8 nyelv közül 5 indoeurópai, köztük három elég közeli rokon (tehát semmit nem mond az összehasonlítás, az eltérések véletlenek is lehetnek), de ha pl. köztük lett volna a poliszintetikus eszkimó is, melyben egy szó egy mondatot is jelenthet, rögtön kiderült volna, hogy hülyeség ez az egész. Az is érdekes, hogy az angol áll az első helyen, amikor angolul sokszor 4–5 szó az, ami pl. spanyolul csak kettő...
Mindegy, lehet, hogy csak én nem értem.
2
ppeli.geo
2011. szeptember 9. 08:40
@El Mexicano: A nyelvek gyorsaságát a szótag/másodperc egységben mérték, és természetesen a történet előadásának hosszúságában - ahogy én értem. Így az is fontos, hogy milyen hosszúak maguk a szótagok, és hogy mennyi információt kódolnak, nem csak az, hogy milyen gyorsnak tűnik egy beszéd.
A kérdésnek nem sok köze van ahhoz, hogy egy nyelv analitikus-e vagy poliszintetikus. A japán nyelv által megengedett szótagok száma például sokkal kevesebb, mint az angolban - talán ha egy tizede. Többre van belőlük szükség az információ lekódolására, ahogy a kettes számrendszerben is hosszabbak a számok, mint a tízesben.
Az eszkimó nyelvekben pedig hiába egy szó egy mondat, ha annak az egy szónak ugyanúgy nagyon sok szótagja van, mint más nyelvek mondatainak.
Az azonban valóban komoly hibája a tanulmánynak, hogy csak három nyelvcsaládot érint. Ez egy első megközelítés. Feltételezném, hogy lesz folytatása...
3
El Mexicano
2011. szeptember 9. 09:10
@ppeli.geo: Egy több információt kódoló szóban értelemszerűen annyival több a szótag is, tehát ebből a szempontból majdnem minden nyelv közel azonos értékeket kellene, hogy adjon. Bár nem ismerek olyan nagyon sok nyelvet, de ha pl. a spanyolból indulunk ki, mondjuk egy egyszerű példával:
soy (1 szótag) = 'vagyok', kijelentő mód, jelen idő, egyes szám, első személy;
fui (1 szótag) = 'voltam', kijelentő mód, befejezett múlt, egyes szám, első személy
A kérdés, ami a fenti példából egyből felmerül, hogy mit tekintünk információnak. Ha azt, hogy ez az egy szótag jelöli az igemódot, az igeidőt (egyúttal a szemléletet), a számot és a személyt, akkor ez legalább 4 információegység. De ha úgy tekintjük, hogy csak a szó jelentését nézzük összességében, akkor csak egy vagy kettő. De akárhogy is vesszük, ugyanez viszont az angolban mindenképpen legalább két szótag: I am, ill. I was.
Én pl. gyakorlati tapasztalatból is tudom, hogy a fordításoknál, főleg a rövidebb szövegeknél, sokszor bajban vagyok, mert magyarul (ami ugye nem szerepel a felmérésben) sokkal hosszabb valami, mint spanyolul (ha precízen akarom fordítani), a hosszabb szövegeknél ez általában nem gond, mert kiegyenlítődik, de még így is elő szokott fordulni, hogy a magyar fordítás fél-egy sorral hosszabb lesz. Tehát szerintem, ha a magyar benne lett volna a felmérésben, akkor ez az elmélet rögtön megdől, hiszen eléggé lassan beszélünk, sok szótaggal, hosszú szavakkal, és ennek ellenére nem mondunk többet, mint fenti nyelveken. :)
4
El Mexicano
2011. szeptember 9. 09:40
@El Mexicano: Természetesen az első mondatom úgy értendő, hogy szűk határok között (lényeg, hogy egyetlen szótagba nem lehet túl sok információt tömöríteni, tehát az információtartalom növekedésével viszonylag arányosan növekszik a szótagszám is).
5
Nước mắm ngon quá!
2011. szeptember 9. 11:33
@ppeli.geo:
A kérdésnek nem sok köze van ahhoz, hogy egy nyelv analitikus-e vagy poliszintetikus. A japán nyelv által megengedett szótagok száma például sokkal kevesebb, mint az angolban - talán ha egy tizede. Többre van belőlük szükség az információ lekódolására, ahogy a kettes számrendszerben is hosszabbak a számok, mint a tízesben.
---
Ezzel az érveléssel nem feltétlen lehet egyetérteni, az emberi nyelv információ kódolása (szóalak - jelentés) nem egyértelmű leképeződés.
Míg egy bitsorozat (az adott kontextusban, pl. egy fájlban) ugyanazt jelöli, pl. az ASCII 111 1000 mindig a (kis) 'x' karaktert jelöli (feltéve, hogy az adott fájlt ASCII kódolásúnak tekintjük), addig a japán nyelv 'hana' hang alakja akár egy mondaton belül kétszer kétfélét (virág; orr) is jelenthet. Hogy ne bonyolítsuk feleslegesen a dolgot, egy magyar példa a homofon 'ég' szóval:
Ég a ház és az ég felé száll a füst.
A szótagok alacsonyabb száma a japánban csak azt eredményezi, hogy sokkal több a homofon szó, mint más nyelvekben.
6
ppeli.geo
2011. szeptember 9. 12:17
@Nước mắm ngon quá!: persze, de utána a homofon szavak jelentését egyértelművé kell tenni, ami általában további szótagokat kíván... vagy nyelvtani szerkezeteket, ami megint újabb szótagokat kíván,
a számrendszeres példa persze nem pontos, de nagyjából vszínűleg áll
7
Nước mắm ngon quá!
2011. szeptember 9. 12:23
@ppeli.geo: Lsd. a lenti magyar példamondatom.
Az ég mindkét jelentése egyértelműen kiderül. Nem kell azt mondanom, hogy "Tűzzel ég a ház és az égbolt felé száll a füst." Vagyis nem feltétlenül kell magyaráznom, hogy a homofon szó melyik jelentését használom, a mondat szavai alapján a címzett el tudja dönteni, melyik jelentésben használták.
8
bibi
2011. szeptember 9. 19:39
Nagyon érdekes cikk. Pl. az is következik belőle, hogy a "címzett" agya nem a szótagszám sebessége szerint dolgozza fel a hallottakat, hanem a jelentés-tartalom sebessége alapján. Felvetődik a kérdés, hogy a szóbanforgó mutató hatással van e a kultúra jellemző vonásaira (és vica versa). És persze hiányolom a finnugor nyelvek felvételét a vizsgálatba. Mithogy, állitólag szegről végről rokon lehet a japán nyelvvel.
9
tenegri
2011. szeptember 9. 20:17
A leglassabb természetesen az óent nyelv lenne, nem is tudom hogy hagyhatták ki :) Mindenesetre én nem igazán értem hogy sikerült mérni az információsűrűséget - nekem elsőre ez elég szubjektívnek tűnik. De majd talán kiderül, ha elolvasom az eredeti cikket.
10
El Mexicano
2011. szeptember 9. 22:39
@tenegri: Szerintem ez az egész komolytalan (lásd a 3. hozzászólást), semmi alapja nincs. Az sem igaz, hogy a spanyolt sokkal gyorsabban beszélnék, mint más nyelveket, csak akusztikai csalódás... ráadásul ez nyelvjárásfüggő is (pl. a latin-amerikaiak sokkal lassabban beszélnek, mint az európai spanyolok). De pl. ott van a közeli rokon nyelvek: ha az egyikben lekoptak a szavak utolsó szótagjai, a másikban nem, akkor eltérő eredményt adna a felmérés, holott semmilyen lényeges különbség nincs a két nyelv között (pl. katalán és spanyol). De itt a magyar is, ami aztán végképp felrúgná ezt az egész elméletet...
11
Pesta
2011. szeptember 10. 08:24
Ezen nincs mit vitázni. Van a projekt, és van rá pályázati pénz. Úgy kell magyarázni az előbbit, hogy az utóbbiról mindenki megfeledkezzen.
12
siddharta
2011. szeptember 10. 13:40
Lassan két éve Kínában élek: még találnom kell valakit aki ilyen lassan beszél. Bááár, szüneteket valóban tartanak, talán többet és hosszabbakat, így valóban kijöhet az 5.18 szótag/s.
13
najahuha
2011. szeptember 10. 14:13
A mássalhangzótorlódások önmagukban is beszédfolyamlassítók.
Ugyanakkor nevükből adódóan is: MÁSSAL-hangzóak. Vagyis mindenképpen ott van mellettük egy MAGÁNhangzó, így pedig már SZÓTAG objektív valóságához jutunk, függetlenül attól, milyen rövid ideig tartott a két mássalhangzó kiejtése.
A nagy különbségek föltehetően a szótag szubjektív megítéléséből fakadnak.
Egyébiránt nem tesz jót a tartalmas és szépen megfogalmazott, egész mondatos gondolkodásnak és beszédnek a MINDENT LEÍRUNK megoldás, mivel egész egyszerűen kevesebb munka jut az agynak, ezáltal a hanyag, tőmondati beszéd kerül előtérbe, ami meg a gyors beszédet generálja. ( A túl sok fölösleges hangi és képi inger okozta felfokozott életritmus mellett)
A nyelvi beszédgyorsasággal MARIO PEI amerikai nyelvész foglalkozott behatóbban az 1960-as években.
Megállapítása szerint az 1890-es évekhez képest a beszédtempo majdhogynem a duplájára nőtt.
( Mindezekről magyar vonatkozásban GÓSY Mária és csapata foglalkozik kellő részletességgel) .
A gyorsulás okát részben abban látni, hogy a 19. századtól a 15-20 %-os írástudás mértéke elérte a 75-80-95 %-ot, amiben az olvasás készsége a hatalmas gyakorlás révén a deklaratív (explicit) memóriából részben áttevődik a nem deklaratív (implicit) memóriába, mint ahogy az írás maga is. Ez egy komoly társadalmi visszahatást , kölcsönös viszonyt is kifejt.
Ugyanakkor a veszélyei is fennállnak, hiszen az egészt kitevő egyének nem egyenlő mértékkel -sebességgel képesek ezek megtanulására és felfogására. Akik lemaradnak, nagy százalékuk kerül a funkcionális analfabetizmus hálójába. ( ez ma már sajnos a fiatalok körében 30 % !! )
A megismerés és a leülepedés ( = a kellő helyen való eltárolódás és kellő kapcsolat az agyban) az alapja a biztos és jól működő készségnek. Ha ez nincs meg, a készség megbízhatatlanná válik. Az egyén részéről ez kiváltható más funkcióval illetve megkerülhető, de tartósan úgy az egyénnek, mint a közösségnek hátrányára válik.
14
najahuha
2011. szeptember 10. 16:55
Egyetértek azokkal, akik azt mondják, az információsűrűség ilyen viszonylatban nem igazán EGZAKT mérce.
Tudniillik a dolgokat általában nem lehet egyik nyelvről a másikra egy az egyben fordítani. Márpedig a pontos mérhetőségnek ez lenne az egyik legalapvetőbb kritériuma. Főleg, ha tizedestörtekben és másodpercekben folyik a mérés.... ( Ez nagyjából olyan hatású, mint a célbaugrás egy magasépület tetejéről.. Semmi nem garantálja, hogy mindig a célkeresztbe sikerül... Próbálkozni és nagyokat mondani persze lehet.)
Az információsűrűség TECHNOLÓGIAi fogalom, ( bit / inch) így aligha van keresnivalója a NYELVek terén, ahol a szavak mögött megbúvó információk többdimenziósak, ( primer jelentés, átvitt jelentés, érzelemhordozás, emlékkapcsolat, illattársítás ) és KULTÚRÁNKÉNT eltérőek.
Gyerekek rajzai által tudnám érzékeltetni:
Az európai gyerekek nagyjából méretarányosan rajzolják le az tigrist és az elefántot. Ellenben az indokínai gyerekeknél a tigris jóval nagyobb mint az elefánt. Ugyanis míg a tigris egy veszélyes állat, ezt a nagyságával jelzik, az elefánt viszont jobbára háziállatként él, ezért veszélyességi faktora is jóval kisebb.
Ugyanez látható még az afrikai gyerekeknél is az oroszlán esetén, noha ott az elefánt nem éppen háziállat ( és az afrikait nem is lehet háziasítani.)
Az európai gyerekek csak az állatkertekben látták ezeket az állatokat, így a hozzájuk fűződő kapcsolat másodlagos információs szintű.
15
najahuha
2011. szeptember 10. 17:01
.
Mert mondjuk a
F I A I É I R Ó L szó információsűrűsége mennyi ??
És ezáltal most szabad-e véleményt formálni akár a magyar nyelv tömörségének mértékéről?
Szabadni szabad, de az egzaktság tekintetében nem érdemes.
16
najahuha
2011. szeptember 10. 17:39
.
De vehetjük a hétköznapi mondatot:
" A mama ebédet csinál."
Más információtartalma van egy angolnál, más egy spanyolnál, olasznál, kínainál, más egy magyarnál. Más volt régebben, és más napjainkban.
Mert jelentheti: "a mama bedobott a mikróba egy adag pizzát"
meg jelentheti azt is, hogy "a mama föltette a levest főni, majd nekiállt galuskát szaggatni, miközben egy másik lábosban már rotyog a pörkölt..."
17
bibi
2011. szeptember 10. 17:43
Szerintem a szótagolás a kiejtés bizonyos szakaszolását jelenti, aminek "darabszámát" elég könnyű megszámolni. A percenkénti szótagszám egyfajta sebesség amit szintén elég könnyű megmérni. Nem értem, hogy mi ez a nagy elutasítás. Pl. a "thank you" japánul "a ri ga to u". Itt pl. 2 szótagszám áll szemben 5 szótagszámmal. Az angol hajlamos bizonyos hangok elhúzására, éppen talán mert túl tömör lenne ha nem húzna el szavakat, a japán pedig nem hajlamos:
www.youtube.com/watch?v=y_qkPy5CUKs
18
najahuha
2011. szeptember 10. 18:14
@bibi: Minden nyelvből kiválasztható - érdekünknek megfelelően !- egy olyan szó-pár , amely hol az egyik, hol a másik nyelvben lesz magasabb szótagszámú.
LEGSZEBB (2 szótag) -- MOST BEAUTIFUL (4 szótag, de a 'BEAU..." -nál bárhogy siessen is az ember, magánhangzó kerül oda, hiszen a "BJÚ" alapból "B>i<JÚ"-ként hangzódik, vagyis ott van egy nagyon röviden ejtett "i". Tudniillik fizikai képtelenség a "BJ" kiejtése magánhangzó nélkül. /Ezért is mássalhangzó a nevük./ Ilyen alapon viszont az angolban akár 5 szótagot is jegyezhetünk.)
Ugyanakkor például a magyar nyelvből véve, az sem mindegy szótagszámilag, hogy LO-Ú-VAL (3) vagy LÓ-VAL (2) ...
19
El Mexicano
2011. szeptember 10. 18:20
@bibi: Az egy dolog, csak éppen semmi értelme nincs a szavak információtartalmáról a szótagszám alapján beszélni, főleg szótagok információsűrűségéről, mivel senki nem tudja, hogy mit ért ez alatt. Az egy szótagos izoláló nyelvekben van egyedül értelme ennek az egésznek, mivel ott valóban minden egyes egy szótagú szó valamilyen információt hordoz, melyből összeáll a mondat. De most azt, hogy egy önálló jelentéssel bíró szó mondjuk a spanyolban két szótagú, az angolban pedig egy, teljesen irreleváns, mivel itt a tőszó mint önálló szemantikai egység számít, nem pedig a szótag. Megint más az agglutináló nyelvekben, ahol szótőre és toldalékokra bonthatóak a szavak, és ahol szintén nagyjából azt lehet mondani, amit az izoláló nyelveknél, hogy a szótő és a toldalékok egy-egy információegységnek felelnek meg, de flektáló nyelveknél nincs értelme erről beszélni.
De ha már említed a japán példát, az arigato a portugál obrigado átvétele (tehát még csak nem is japán szó), és az obrigado a latin OBLIGATUS (ob|liga|tus), 'le|kötelez|ett' folytatása. Viszont amint ezt a japán átvette, el is veszett a szóelemek jelentése, innét kezdve tök mindegy, hogy hány szótagú. Ugyanez a spanyolban gracias (< lat. GRATIAS [AGO] 'hálákat [teszek]'), de ezt megintcsak nem lehet értelmezni a szótagok jelentése szerint (mit jelentene a gra- és a cias külön-külön?).
És mindehhez hozzájön az is, hogy teljesen mindegy, hogy ezeket milyen gyorsan mondják ki, attól nem lesz sem több, sem kevesebb a jelentése...
20
najahuha
2011. szeptember 10. 18:21
@bibi: A videóról jutván eszembe az a kutatási munka, amiben leírták, az angol beszédnél a szavak indítása KÉSLELTETETT , ugyanis az agyban lévő kapcsolt kép, illetve az ÍRÁS eltérése a kiejtéstől bizonytalansági tényező. Ennek a bizonytalansági tényezőnek a tisztázására van szüksége az agynak erre a késleltetésre.
A magyar nyelv esetén is föllelhető egy szűk helyen: a teljes hasonulásnál, amit az írás nem követ.
21
El Mexicano
2011. szeptember 10. 18:26
... de azt is mondhatnám, hogy ha ugyanazt a spanyol szöveget egy hadarós spanyol mondja el, akkor annak "kevesebb információtartalma" van, ha pedig egy lassan beszélő argentin, akkor többet fog ettől jelenteni? :)))
22
Ed'igen
2011. szeptember 10. 18:36
Nekem már az is kérdés, hogy mi az az információ, amit átad egy nyelv egységnyi idő alatt. A sok-sok konnotáció, a stílusérték stb. miatt szerintem lehetetlen megmérni, hogy mi is az az információ, jelentés amit átadunk egy közléssel. Nincsen konnotáció és kultúra semleges közlés ugyanis. Vagy én nem tudok elképzelni ilyet természetes nyelvekben.
23
Nước mắm ngon quá!
2011. szeptember 10. 18:46
@najahuha: Akár hogyan számolom nem jön ki az 5 szótag. Diftongusokról biztos hallott már a kollega :)
24
Nước mắm ngon quá!
2011. szeptember 10. 19:12
@bibi:
Az arigato ありがとう 4 szótag, az 'ou' hosszú ejtést jelöl.
Másrészt a japánok is hajlamosak bizonyos szavak nyújtására. Anoooo ;) De ugyanígy néhány szótag elnyelésére is. pl. a su す, shi し szótagokban a magánhangzó néha elmarad. Ezentúl a tévéadások stb. nyelve a semleges hivatalos stílust alkalmazza, ebben pedig használni kell a hosszúalakokat, desu です, masu ます. Ha közvetlen, informális stílust használunk, ezek elmaradnak vagy rövidülnek. Az 'Hogy vagy/van?' お元気ですか?'(form.) és a 元気? (inform.) világosan mutatja ezt.
25
Nước mắm ngon quá!
2011. szeptember 10. 19:15
@Nước mắm ngon quá!:
Még egy gondolat az angol-japán összehasonlításhoz:
Az angolban viszont kifejezetten megengedett az aposztrofálás és ezzel komplett szótagok egyetlen betűvé (rendszerint önálló szótagot nem jelentő mássalhangzóvá) redukálása.
I'd (I would vagy I had)
I'll (I will)
it's/that's (it is, that is, stb.)
26
El Mexicano
2011. szeptember 10. 19:17
Inkább az lenne az érdekes kérdés, hogy vajon a nyelv szerkezetében, avagy a beszélők genetikájában keresendő annak az oka, hogy egy nyelvet milyen gyorsan (és milyen akcentussal) beszélnek. Én továbbra is hiszek az utóbbiban.
27
Nước mắm ngon quá!
2011. szeptember 10. 19:32
Még egy gondolat a távol-keleti nyelvekhez, különösen a japánhoz:
igaz, hogy egy azonos jelentésű japán és angol mondat esetében a japán több szótagot fog használni, de a japán szótagok rövidebbek az angol szótagoknál, mivel csak magánhangzóra vagy n-re ん, ill. az elnyelt szótagvégi magánhangzók esetében réshangra végződhet. A japánban nincsenek mássalhangzótorlódások, ugyanígy a kínaiban (mandarin) és a vietnamiban sem. E két utóbbi nyelvben a szótagok végén csak nazális hang vagy a kínai esetében retroflex 'r' képzelhető el. Egyik nyelvben sem kezdődhet a szótag pl. úgy, hogy 'str....'.
28
najahuha
2011. szeptember 10. 20:27
@Nước mắm ngon quá!: Sőt mi több, TRIFTONGUSokról is......
No de miből is áll a diftongus ?
Legalábbis a VALÓDI kettőshangzó ..
Egy (zártabb) FÉLHANGZÓból és egy VALÓDI (nyíltabb) magánhangzóból. Ez utóbbit tekintik a valódi szótagalkotónak. Ugyanakkor a fenti vizsgálatok tekintetében EZt a "félhangzót" SEM SZABADNI kihagyni a számításból... Már ha annyira számítanak a SZÁZADNYI eltérések.. Már pedig számítanak, hiszen számos nyelvben századnyi szintű az eltérés...
Egyébként a VALÓDI kettőshangzók nyelvtörténetileg KÉT KÜLÖN hangból álltak. Így eszerint Jogos az igényem a pontosságot illetően.
29
najahuha
2011. szeptember 10. 20:40
@Nước mắm ngon quá!:
Ez igaz.
Csakhogy ezeket akkor képesek megérteni nagy tömegben, ha a hozzá tartozó agyi rögzítés is megtörtént.
Tapasztalatból tudjuk, megtörtént, annak okán , hogy az angol nyelv ma a világ közlekedőnyelve, gyakorlatilag globálisan a legnagyobb számban beszélt nyelv. Ha nem így történt volna, az említett rövidítések a megjelenési helyén lévő társadalomra korlátozódtak volna, terjedése pedig jóval lassabb lett volna, kisebb hatókörrel.
Ehhez mérhető rövidítési igyekezetre a magyarban is találni elrettentő példát, amit csak lehet kicsinyítővel mondani: cuki pofi, jó a rucid.- Haggy' má' te ribi . Szól a telcsid. Talizunk holnap.... stb..stb..
Ez sajnos nem csupán a fiatalok egy viselkedési /kultúra rétegéhez tartozó beszédforma, hanem a huszonéves korosztálytól LEFELÉ általános tendencia, ami egyértelműen kezd benyomulni a feminim férfiak nyelvkészletébe is.
30
Nước mắm ngon quá!
2011. szeptember 10. 20:40
@najahuha: Jó, akkor a tetriftongusokat nem feszegetem. Bár a 'most beautiful'-t még mindig nem tudom 5 szótagnak számolni.
31
Nước mắm ngon quá!
2011. szeptember 10. 20:47
@najahuha: Nem hiszem, hogy a feminin férfiak nyelvhasználatával vagy a szavak lerövidítésével baj lenne.
Amikor pl. kisgyerekekkel beszélünk (akár mint férfi), törekszünk a szavak rövid, gyereknyelvi változatait használni, röfi (sertés, disznó) maci (medve), nyuszi (nyúl), laszti (labda), fagyi (fagylalt), suli (iskola), ovi (óvoda), stb. Ezzel önmagában még nincs baj.
A baj az, ha a szavak, a kommunikáció igénytelenné, tartalmatlanná válik. Szerintem inkább erre gondolhattál.
32
najahuha
2011. szeptember 10. 21:00
@Nước mắm ngon quá!:
Írta:
"I'd (I would vagy I had)
I'll (I will)
it's/that's (it is, that is, stb.)"
És éppen ezek miatt indítja szavait KÉSLELTETÉSSEL az angol , ugyanis az ilyen kiejtések összeütköznek MÁS szavak teljesen más értelmével.
I WOULD # I HAD --> I'D # I' D stb.... # EYED # ID # ˛*AID
I'LL # stb..
IT'S # ITS / EATS stb...
de a WE'LL sem egyenló a WILL-el......mint ahogy a HOW'S # HOUSE ....
A helyzet nem hogy javulna, inkább bonyolódik, az agy másodlagos értelmezési mezeire lép...
És még a diftongusra visszatérvén:
a diftongus HOSSZAN kitartott egy sima szótaghoz képest, ezáltal a beszédütemet lassítja .
bay, hey, fate,buy, high, ride, write,bough, how, pout,beau, hoe, poke,beauty, hue, pew, new
33
najahuha
2011. szeptember 10. 21:01
34
El Mexicano
2011. szeptember 10. 21:13
@najahuha: "No de miből is áll a diftongus? Legalábbis a VALÓDI kettőshangzó. Egy (zártabb) FÉLHANGZÓból és egy VALÓDI (nyíltabb) magánhangzóból" – ideális esetben így van, de nem mindig, és nem is ez a lényege, hanem egyszerűen az, hogy egy szótagban ejtünk ki két eltérő magánhangzót. Ez általában valóban egy félhangzó és egy szótagalkotó magánhangzó, de lehet két egyformán zárt hang is, és az sem kötelező, hogy az egyik félhangzó legyen. Pl. a spanyol cuidar szóban az ui diftongus két hangja kb. ugyanolyan hosszú, nem igazán lehet arról beszélni, hogy melyik a félhangzó – konvencionálisan persze az ui és iu esetén mindig az első számít félhangzónak, de a kiejtés nem mindig ezt mutatja. A lényeg tehát az, hogy itt az ui csoport egy szótag hosszúságú.
35
najahuha
2011. szeptember 10. 21:14
@Nước mắm ngon quá!:
Írta:"Nem hiszem, hogy a feminin férfiak nyelvhasználatával vagy a szavak lerövidítésével baj lenne."
Önmagában ez nem is lenne baj. A gond az IGÉNYTELENSÉG és az EGYSÍKÚSÁG. A gügyögő szint pszichológiai értelemben egyáltalán nem ajánlott egy kor után. (beszűkültséghez vezet..)
Írta:"Amikor pl. kisgyerekekkel beszélünk (akár mint férfi), törekszünk a szavak rövid, gyereknyelvi változatait használni, röfi (sertés, disznó) maci (medve), nyuszi (nyúl), laszti (labda), fagyi (fagylalt), suli (iskola), ovi (óvoda), stb. Ezzel önmagában még nincs baj."
Ez teljességgel rendjén van.
Írta:"A baj az, ha a szavak, a kommunikáció igénytelenné, tartalmatlanná válik. Szerintem inkább erre gondolhattál."
Egyetértek. Sőt, kiegészíteném a befejezetlenül kimondott mondatokra. Amikor a beszélő már gondolatban jóval előrébb tart, és mivel a szavak torlódnak, a mondat vége kimondatlan marad, rábízva a hallgatóra a befejezést. Ugyanakkor ott sem fejeződik be az értelmezés, mert a következő mondatra kell figyelni.
A BEFOGADÓképességnek / FELFOGÓképességnek is van BITEKben mérhető határa, még akkor is, ha a fogalmakat a direkt memóriából kapjuk elő. Ha információtúlcsordulás történik, érdektelenség okán a figyelem lankad (ugyanez történik a sok ismétlő / körbejáró--redundáns/ gondolatsorok esetén is) , a társalgás szimpla "ÜHÜM....ÜHÜM....HÁT PERSZE....IGEN...IGEN..." viselkedési szerepbe csap át.
Ezért fontos a JÓ , MEGFONTOLT és ÉRDEKES mondat, nem csupán az üres locsogás.
36
najahuha
2011. szeptember 10. 21:26
@El Mexicano:
Írta: "Pl. a spanyol cuidar szóban az ui diftongus két hangja kb. ugyanolyan hosszú, nem igazán lehet arról beszélni, hogy melyik a félhangzó – konvencionálisan persze az ui és iu esetén mindig az első számít félhangzónak, de a kiejtés nem mindig ezt mutatja. A lényeg tehát az, hogy itt az ui csoport egy szótag hosszúságú."
A cuidar [kwiˈdar] esete is igazolja, ha a diftongus mindkét tagja egyenlő hosszú, ( és ez nem két félhangzót jelent !!) akkor eleve hosszabb kiejtésről beszélhetünk. Ráadásul a második szótag hangsúlyi mivolta törtmásodpercnyi elsőszótagi nyújtást is előidéz.
A "bonckés" szempontjából én 3 szótagnak venném.
37
najahuha
2011. szeptember 10. 21:38
38
Nước mắm ngon quá!
2011. szeptember 10. 21:45
@najahuha: Az aha-aha-aha visszacsatolásokra tudnék ellenpéldát is mondani, méghozzá akadémiai szintű társalgásból, a dán nyelvben pl. gyakori, hogy egy hosszabb gondolatmenetet a címzett rendszeresen 'ja' (ejtsd. kb. 'je') .…szóáradattal kísér, biztosítva, hogy követi a hallottakat. Eleinte zavaró volt hallani, de végülis van funkciója. Viszont itt elkanyarodunk a cikk témájától.
Valami populárisabb:
www.youtube.com/watch?v=eM6zPikfOEs&feature=related
39
najahuha
2011. szeptember 10. 22:09
@Nước mắm ngon quá!:
Annyiban csatlakozik az általam mondott és az általad hozzáfűzött a fenti témához, hogy éppen az "AHA meg az ÜHÜM " -höz hasonló visszajelzések adnak muníciót a további gyors beszédre. Hiszen ha "érted", mert ezt jelezted vissza, amit mondok és amilyen gyorsan mondom, akkor minden "OKÉ", "lököm a sódert" ( Mert a világot és magunkat el kell adni.....minden erről szól: lukat beszélni a másik hasába..)
A videóra: versenyt lehet űzni belőle, játéknak elmegy. És akkor az angolnál előnyösebb nyelveken vajon mennyi lenne a teljesítmény ?
Persze én úgy mérném a dolgot, hogy egy kontrollcsoportnak az elmondottak lényegét vissza is kellene mondania.
Így máris kiderülne az elmondottak értelemhűsége is.... Mert a folyékony beszéd gyorsítása nyilván elmehet a teljes halandzsa szintjéig is....
40
najahuha
2011. szeptember 10. 22:27
Ha valaki beszéd közben 1 másodperc alatt 9 hangot mond ki, annak mondandóját az emberek 94 százalékban értik meg. Ha viszont tizenkilenc hangot ejt ki ugyanennyi idő alatt, akkor a mondanivalónak csak a 85 %-a jut el a hallgató tudatáig. Ez a gyors beszéd.
Azonban ha valaki össze is mossa a hangokat és a szótagokat, elhagyja a szóvégi ragokat, hangsúlytalanul, monoton hangon beszél, jelentősen csökkenti az érthetőség mértékét. Ezt már hadarásnak hívjuk.
A hadaró emberkék általában figyelmetlenek, szórakozottak, nehezen tudnak koncentrálni. Gondolkodásuk kusza. Átlagos vagy magas intelligenciával (IQ) rendelkeznek. (Ellenben EQ-juk alacsonyabb) Főleg az úgynevezett "praktikus" intelligenciájuk kiemelkedő: az életvitelben nagyon tájékozottak. A hadarókat minden érdekli, de ez az érdeklődés nem túl mély, könnyen elterelhető. Általában ingerlékenyek, nyugtalanok, rendkívül impulzívak. Könnyen teremtenek kapcsolatot, célratörők, öntudatosak és makacsok.
A hadarást kutató szakemberek a legjellemzőbb tünetnek a monotóniát tartják.
Mi is a monotónia? Ez tulajdonképpen azt jelenti, hogy beszéd közben egyáltalán nem, vagy csak csekély mértékben változik a hadaró hangmagassága, "színtelen" a beszéde, nincs "dallama", unalmas. A hadaró természetéből fakadó figyelmetlenség miatt az olvasás is zavart szenvedhet. Ugyanúgy, ahogyan a beszédben kihagynak hangokat, szótagokat, összemosnak egy-két szót, az olvasásban is "produkálják" ezeket a tüneteket. A szegényes szókincsük, az emlékezeti működésük gyengesége és a
lényeglátásban mutatkozó hiányosság miatt előfordul, hogy a szöveg megértése is nehézséget jelent számukra.
A hadaró írása az elmosódott artikuláció "tükörképe". Azaz, ahogyan azokat a hangokat sem formálja meg, amiket kiejt, úgy a betűk megformálásával sem "fárad". A leírt betűk jellegtelenek, gyakran felismerhetetlenek. Írásában is megjelennek a nyelvtani hibák, a szavak kihagyása, felcserélése, összevonása.
41
najahuha
2011. szeptember 10. 23:12
42
najahuha
2011. szeptember 10. 23:15
Matematikai képletet dolgoztak ki brit tudósok annak megállapítására, hogy milyen a legkellemesebb beszédhang az emberi fül számára. A képlet a hangszín, a beszédsebesség, a hanglejtés, a frekvencia, a percenkénti szómennyiség kombinációján alapul.
A legjobb megoldás: percenként 164 szavas maximális sebesség 0,48 másodpercnyi szünetekkel a mondatok között, az intonációnak pedig hullámzónak, nem pedig emelkedőnek kell lennie.
A képlet kialakításához félszáz ember zsűrizett: elmondta benyomásait, rangsorolta az egyes személyek beszédét.
Ami a konkrét mintákat illeti, Jeremy Irons színész közelítette meg legjobban az ideális eredményt, pedig ő sem lassú: 200 szó per perces a beszédsebessége, azaz 36-tal gyorsabb az optimálisnál, viszont 1,2 másodperces mondatközi szüneteket tart, vagyis csaknem két és félszeresét az ideálisnak.
Az élmezőny a nők közül Dame Judi Dench színésznőből és Mariella Frostrup rádióbemondóból áll, a férfiaknál Irons mellett Alan Rickman színész találtatott a legkellemesebb hangúnak.
A kutatók szerint a magasba és mélybe hullámzó hanglejtés intelligenciáról tanúskodik, míg az emelkedő tónus gyengeségről és bizonytalanságról. A lassúbb, mélyebb hangszínű beszéd bizalmat kelt - adta hírül a BBC.
43
El Mexicano
2011. szeptember 11. 08:12
@najahuha: Hát nem egészen. A cuidar esetén a cui- pontosan ugyanolyan hosszú, vagy rövidebb, mint a -dar szótag, mivel a hangsúlyos szótagot nyújtják el, nem pedig a hangsúlytalant.
44
elhe taifin
2011. szeptember 11. 09:03
@El Mexicano:
"az arigato a portugál obrigado átvétele "
Ez inkább népetimológia :)
Az arigató az "arigatai" melléknév jelzői alakjából (arigataku → arigatau → arigató) származik.
45
elhe taifin
2011. szeptember 11. 09:05
@Nước mắm ngon quá!:
"De ugyanígy néhány szótag elnyelésére is. pl. a su す, shi し szótagokban a magánhangzó néha elmarad."
Ezt hívják magánhangzó-zöngétlenedésnek. (母音の無声化)
46
elhe taifin
2011. szeptember 11. 09:25
@elhe taifin: Bocsánat, nem a jelzői, hanem a határozói alakról van szó.
47
IdegenNyelvŐr
2011. szeptember 11. 11:35
@najahuha: "Valódi" kettőshangzóról csak fonetikailag (értsd: artikulációs fonetika) beszélhetünk, ott pedig csak és kizárólag a két magánhangzóból álló kapcsolatot illetheti ez az elnevezés. A fonetika szintjén a félhangzó értelmezhetetlen, hiszen az egy tisztán fonológiai fogalom, a fonológia pedig elvont, kitalált, nem valódi rendszer, így a félhangzót tartalmazó kettőshangzó is csak a fonológia szintjén létezhet, ami miatt nem is lehet valódi, csak elképzelt.
Így a /wi/ fonológiailag felfogható ugyan kettőshangzónak, de fonetikailag a [wi] semmiképpen sem, hiszen a [w] hangot senki sem tartja magánhangzónak.
Ahogy El Mexicano is megjegyezte, a valódi kettőshangzó két tagja nem feltétlenül eltérő zártságú magánhangzó, hiszen a nyelv mozdulhat előre/hátra is (pl. [ʉu]), nem csak fel vagy le. De lehet, hogy egyáltalán nem is mozdul semerre, csak az ajakkerekítés mértéke változik, pl. [ɨʉ].
48
najahuha
2011. szeptember 11. 14:59
49
najahuha
2011. szeptember 11. 15:03
50
IdegenNyelvŐr
2011. szeptember 11. 16:37
@najahuha: Nem tudom, mit szeretnél bizonyítani, én csak arra hívtam fel a figyelmed, hogy ne mosd össze a fonetikát és a fonológiát. Egy hangminta értelemszerűen csak fonetikai bizonyíték lehet, te viszont félhangzókról beszéltél, ami meg fonológiai fogalom. Kézzelfogható bizonyíték a fonológiában nincs, hiszen minden csak megállapodás, analízis kérdése. Ez olyan, mint a matematikában az, hogy minden szám nulladik hatványa egy. Erre sincs bizonyíték, ez csak egy megállapodás. Lehetett volna éppenséggel nulla is...
A linkelt hangmintában a cuidar [kwi-] hangsorral kezdődik, azaz nem kettőshangzó, hanem egy approximáns és egy magánhangzó sorozata van benne. Ha [kui-] hangsorral kezdődne (ami egyébként hallható anyanyelviektől is), akkor beszélhetnék fonetikai értelemben kettőshangzóról. De ettől ez még ugyanannak a /wi/ fonémakapcsolatnak a két létező kiejtésváltozata, fonológiailag nincs különbség köztük. Az meg csak elemzés és érvelés kérdése, hogy fonémikusan /ui/-ként jelöljük, megengedve, hogy az /u/-t realizálhatja az approximáns [w] is az [u] mellett, vagy /wi/-ként jelöljük, hozzátéve, hogy a /w/ realizálódhat [u] -ként is a [w] mellett.
De mivel úgy tudom, a [wi] realizáció a gyakoribb, ezért én fonémikusan is /wi/-ként tartom célszerűnek kezelni, aztán, hogy ezt a legtöbbször approximáns + magánhangzóként realizált hangsort a fonológiában vajon miért érzik helyénvalónak kettőshangzónak tekinteni, az egy másik kérdés.
51
najahuha
2011. szeptember 11. 17:16
@IdegenNyelvŐr:
Erről van szó.
Legalább láttattad, NEM EGZAKTságról, jobban inkább SZEMLÉLETről beszélhetünk csupán..(legalábbis a fonológia tekintetében)
Nem kívánom összemosni a két dolgot, viszont azt is látni kell, mindettől függetlenül a fonológia és a fonetika NEM MONDHAT ellent egymásnak. Főleg egy holisztikus szemlélet felé tartó nyelvkutatásban nem.
















